

Here’s something most AI leaders won’t admit: the majority of AI project failures have nothing to do with the technology itself.
Your models work. Your data scientists are brilliant. Your infrastructure is solid. Yet 60-80% of AI pilots never make it to production. And of those that do, many fail within months.
The culprit? AI governance failures.
We’re not talking about compliance committees or policy documents gathering dust. We’re talking about fundamental architectural gaps that allow AI systems to generate invalid outputs, drift unmonitored, violate business rules, and produce decisions that executives can’t explain to the board.
The real problem: Most companies treat AI governance as an afterthought, something to bolt on after the AI is built. By then, it’s too late. The architecture doesn’t support governance. The outputs can’t be validated. The decisions can’t be traced. And the whole system becomes a black box that everyone’s afraid to touch.
AI governance isn’t a compliance checklist. It’s an engineering discipline that must be architected into your AI systems from day one, with the same rigor you apply to security, performance, and scalability.
In this guide, you’ll learn Pendoah’s Layered Governance Architecture, a framework we’ve proven in production healthcare AI systems. This isn’t theory. We’re sharing the actual architecture, the real tradeoffs, and the specific implementation path that prevents AI governance failures before they happen.
Here’s what you’ll discover:
- The 5 core principles that make AI systems governable by design
- A 4-phase implementation model you can execute in 60-90 days
- Real architecture from StatSafe, a production system processing sensitive healthcare data
- How to give executives strategic visibility without overwhelming them with technical details
- Common obstacles mid-market companies face (and exactly how to overcome them)
Let’s dive in.
Why Traditional AI Governance Fails
Before we introduce our framework, you need to understand why the standard approach doesn’t work.
Governance as Theater, Not Engineering
Most AI governance frameworks look impressive on paper. You’ve seen them:
- Ethics committees that meet quarterly
- Policy documents spanning hundreds of pages
- Point-in-time audits by compliance teams
- Approval workflows that slow everything down
The problem? None of this prevents actual failures.
These approaches treat governance as a layer on top of your AI system. They assume you can check a model once, approve it, and call it governed. But AI systems are dynamic. Models drift. Data changes. Edge cases emerge. What worked in testing fails in production.
The Four Fatal Gaps
Traditional AI governance creates four critical gaps:
1. The Validation Gap
Your model generates an output. Who validates it before it reaches production? Most systems have no automated validation layer. They trust the AI to be correct. When it’s not and it will be wrong eventually, there’s no safety net.
2. The Observability Gap
When an AI makes a bad decision, can you trace why? Most systems can’t. There’s no audit trail of the reasoning process. You can’t debug. You can’t learn. You just know something went wrong.
3. The Context Gap
Does your AI understand your business rules, data schema, and compliance requirements? Or is it generating outputs based solely on statistical patterns? Without context-aware generation, AI produces technically correct answers that violate your actual constraints.
4. The Visibility Gap
Can your executives explain AI decisions to the board? To regulators? To customers? If governance lives only in the technical team, strategic oversight becomes impossible.
These gaps are architectural. You can’t policy your way out of them. You have to build governance into the system.
Introducing Pendoah’s Layered Governance Architecture
Pendoah’s Layered Governance Architecture is a framework for building governable AI systems from the ground up. Instead of auditing AI after deployment, you architect validation, monitoring, and visibility directly into the AI pipeline.
Think of it like security. You don’t build an application and then “add security.” You design with security principles from day one: authentication, authorization, encryption, and logging. Security is layered throughout the architecture.
AI governance works the same way.
Our framework has two core components that work together to make AI systems governable:
| Component 1 | Component 2 |
|---|---|
| Defines what makes AI governable, the architectural patterns you must build into your system. | Defines how to implement those patterns, the practical roadmap from concept to production. |
Together, they give you both the principles (what to build) and the process (how to build it). Let’s explore them further.
Component 1: The 5 Principles of Governable AI
These are the architectural patterns that make AI systems trustworthy, explainable, and controllable. Think of them as design requirements:
- Context-Aware Generation: AI that understands your rules before it generates outputs
- Multi-Layer Validation: Multiple checkpoints that catch errors before production
- Continuous Observability: Full traceability of every AI decision
- Stateful Control: Workflows that maintain context and enforce logic
- Human-Verifiable Outputs: Explainable results executives can understand
Component 2: The 4-Phase Implementation Model
These principles map to a practical implementation roadmap you can execute in 60-90 days:
- Phase 1: Context Loading (Weeks 1-2)
- Phase 2: AI Interpretation (Weeks 3-4)
- Phase 3: Validation & Verification (Weeks 5-8)
- Phase 4: Execution & Monitoring (Weeks 9-12)
Each phase has specific deliverables and quick wins so you can see value before full deployment.
How the 5 Principles Work in Production (StatSafe Architecture)
Let’s break down each principle with real implementation details from StatSafe, a production system we built for healthcare data access.
Principle 1: Context-Aware Generation
The Problem: Most AI systems generate outputs based purely on statistical patterns. They don’t understand your database schema, business rules, or compliance requirements. Result? Technically correct outputs that violate your actual constraints.
The Solution: Use Retrieval-Augmented Generation (RAG) to inject governance context before the AI generates outputs.
How StatSafe Implements This:
StatSafe converts natural language queries into SQL. But it doesn’t let GPT-4 generate SQL blindly. Instead:
- User asks a question in plain English
- Azure AI Search retrieves the relevant database schema
- Schema context is injected into the GPT-4 prompt
- GPT-4 generates SQL that aligns with actual table structures and relationships
The architecture:

Why this matters: The AI understands what columns exist, what data types are valid, and what relationships matter. It can’t generate queries for tables that don’t exist. It can’t request fields that violate your data model.
For your AI system: Before your model makes a decision, load the relevant governance rules. If you’re approving loans, load your lending criteria. If you’re classifying documents, load your taxonomy. If you’re generating code, load your style guide.
Context-aware generation prevents AI governance failures at the source; the AI simply can’t generate outputs that violate your constraints.
Principle 2: Multi-Layer Validation
The Problem: Even with context, AI makes mistakes. Models hallucinate. Logic breaks down. Edge cases slip through. If you trust AI output without validation, you’re one bad generation away from a production incident.
The Solution: Implement multiple validation layers that check outputs at different levels before they reach production.
How StatSafe Implements This:
StatSafe doesn’t execute SQL the moment GPT-4 generates it. Instead, every query passes through four validation layers:
Layer 1: Schema Validation
Does this query reference valid tables and columns? If not, reject.
Layer 2: Syntax Validation
Is this syntactically correct SQL for SQL Server? If not, reject.
Layer 3: Security Validation
Does this query attempt dangerous operations (DROP, DELETE without WHERE)? If so, reject.
Layer 4: Dry-Run Testing
Execute the query against a test dataset. Does it run without errors? If not, reject.
Only after passing all four layers does the query execute against production data.
The architecture:

Why this matters: Multi-layer validation catches different types of errors. A query might be syntactically correct but reference the wrong table. It might pass schema checks, but it contains a security risk. Each layer adds safety.
For your AI system: Identify 3-5 validation checkpoints specific to your domain. For medical diagnoses: clinical guidelines, drug interaction checks, and dosage limits.
For financial recommendations: risk tolerance, regulatory compliance, and portfolio constraints.
Don’t trust AI output. Validate it through multiple lenses before it matters.
Principle 3: Continuous Observability
The Problem: When AI fails, you need to know why. But most systems are black boxes. You see the output. You don’t see the reasoning, the context, the alternatives considered, or the decision path.
The Solution: Implement full traceability of every AI decision using observability tools designed for LLM workflows.
How StatSafe Implements This:
StatSafe integrates LangSmith, an observability platform for AI systems. Every user query generates a complete trace:
- Input: The original natural language question
- Context: What schema was retrieved
- Prompt: The exact prompt sent to GPT-4
- Reasoning: Chain-of-thought steps (if used)
- Output: The generated SQL
- Validation: Results from each validation layer
- Execution: Query results and performance metrics
If something goes wrong, you can replay the entire decision tree. You know exactly what the AI saw, what it thought, and why it generated that specific output.
The architecture:
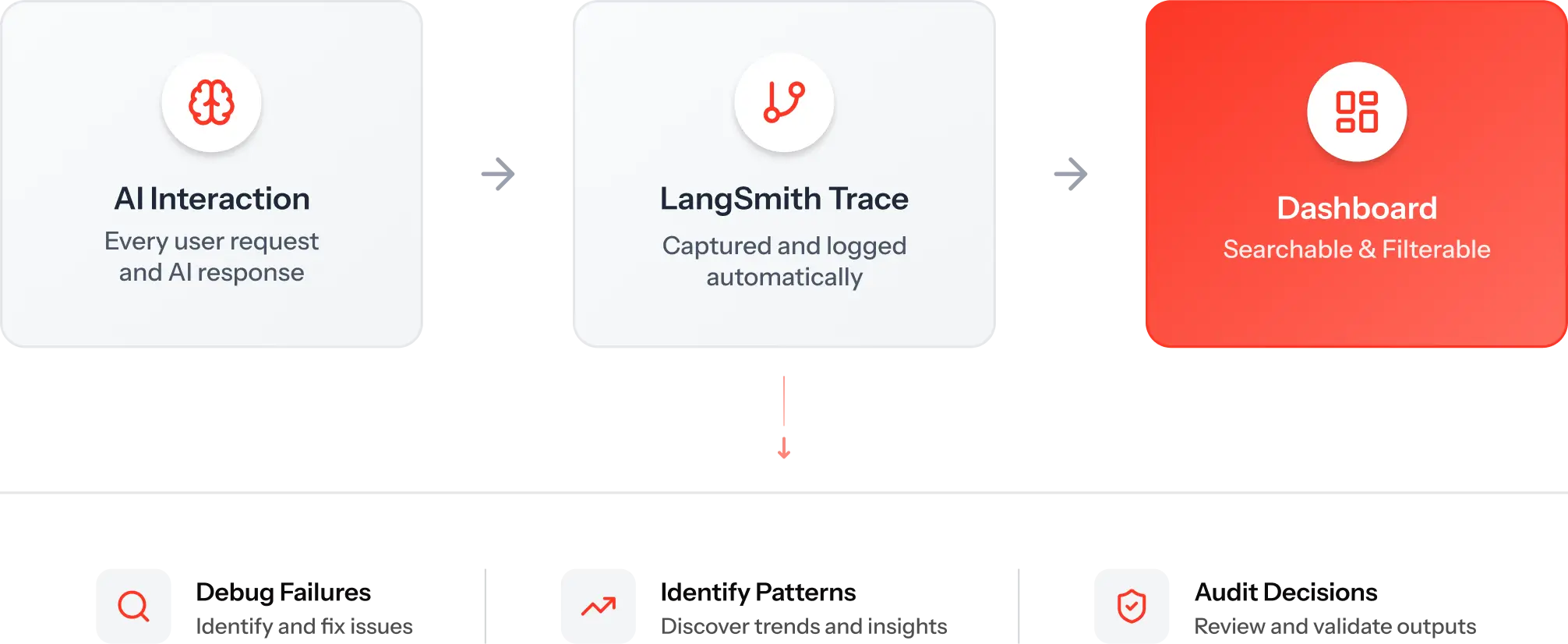
Why this matters: Continuous observability transforms debugging from guesswork into forensics. You’re not asking “what went wrong?” You’re looking at the exact decision path and pinpointing the failure.
For your AI system: Implement logging at every step. Track model inputs, outputs, confidence scores, validation results, and execution metrics. Use tools like LangSmith, Weights & Biases, or MLflow to centralize observability.
AI governance monitoring isn’t optional. Without observability, you’re flying blind.
Principle 4: Stateful Control
The Problem: Many AI systems treat each interaction as isolated. They don’t maintain context across steps. They don’t enforce conditional logic. They don’t handle multi-turn workflows. Result? Inconsistent behavior and lost context.
The Solution: Use stateful orchestration to manage AI workflows with explicit control flow and memory.
How StatSafe Implements This:
StatSafe uses LangGraph, a framework for building stateful AI applications. Instead of a simple “prompt in, response out” flow, it manages multi-step workflows:
Step 1: Parse User Intent
Is this a data query? A clarification request? An invalid input?
Step 2: Conditional Branching
- If query → Retrieve schema → Generate SQL → Validate → Execute
- If clarification → Reference conversation history → Ask follow-up
- If invalid → Provide error guidance → Don’t execute
Step 3: State Management
Maintain conversation context. Remember previous queries. Track user preferences.
The architecture:
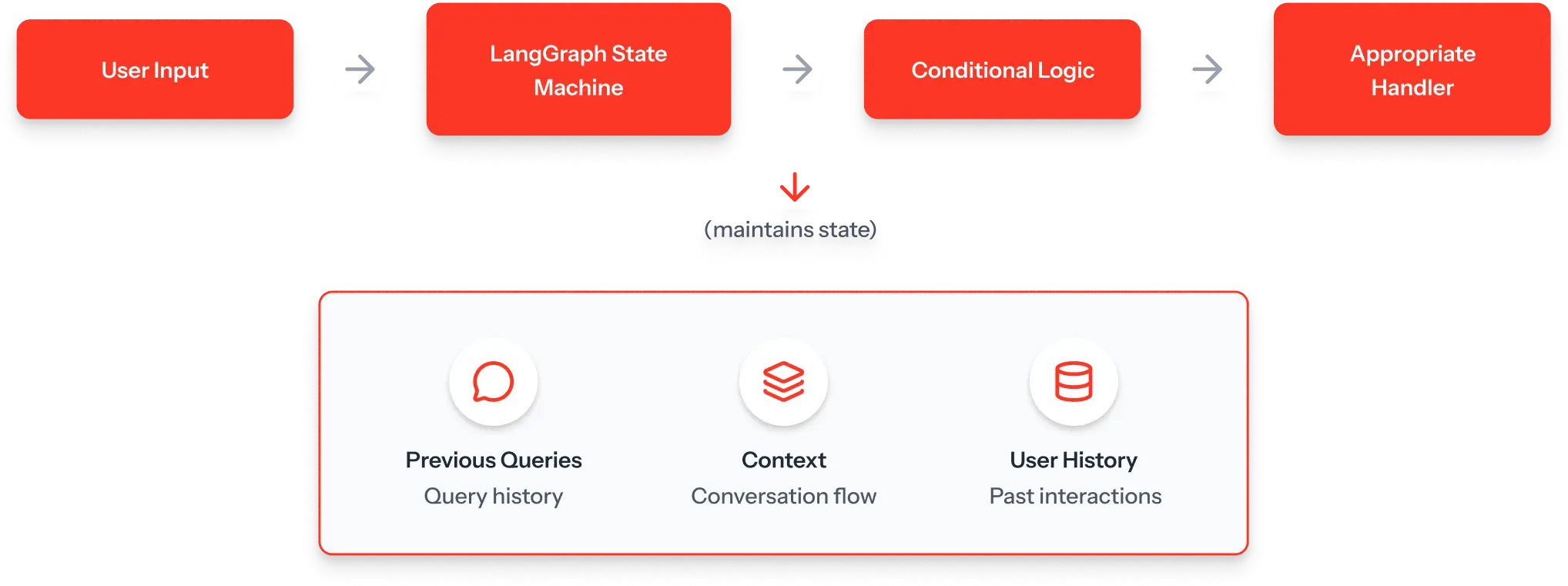
Why this matters: Stateful control prevents AI from making decisions in isolation. The system understands where the user is in the workflow and responds appropriately. It doesn’t lose context mid-conversation.
For your AI system: Map out your multi-step workflows. Where does AI need to maintain context? Where do you need conditional logic? Use orchestration tools like LangGraph, Temporal, or Airflow to enforce workflow governance.
AI governance requires control. Stateful systems give you that control.
Principle 5: Human-Verifiable Outputs
The Problem: Technical teams understand model confidence scores and loss functions. Executives don’t. When the board asks, “How do we know this AI is safe?”, you can’t point to backpropagation. You need human-readable explanations.
The Solution: Design outputs that are intrinsically explainable, not just to data scientists, but to business stakeholders.
How StatSafe Implements This:
When StatSafe generates SQL, it doesn’t just execute the query. It shows:
- The Original Question (natural language)”Show me all prescriptions for patients over 65.”
- The Generated Query (with comments)
-- Finding prescriptions for senior patients
SELECT p.prescription_id, p.patient_id, p.medication
FROM prescriptions p
JOIN patients pt ON p.patient_id = pt.patient_id
WHERE pt.age > 65
- The Validation Results
- Schema valid
- Syntax correct
- Security approved
- Test execution passed
- The Data Preview
First 10 rows of results
Anyone: clinical staff, compliance officers, and executives can verify that this output makes sense.
The architecture:

Why this matters: Human-verifiable outputs enable strategic visibility. Your CTO can show the audit committee exactly how AI decisions are made. Your compliance team can document decision logic. Your executives can trust the system because they can inspect it.
For your AI system: Design outputs that show the reasoning, not just the result. For medical AI: diagnosis + supporting evidence + confidence level + similar cases. For financial AI: recommendation + market analysis + risk factors + regulatory compliance.
AI ethics and governance start with transparency. Make your AI explainable to humans.
The 4-Phase Implementation Model
Now that you understand the principles, here’s how to implement them in your organization. This isn’t a 12-month enterprise project. It’s a 60-90 day sprint designed for mid-market teams.
Phase 1: Context Loading (Weeks 1-2)
Goal: Give your AI the governance context it needs before it generates outputs.
What You’ll Build:
For RAG-based systems:
- Index your governance rules, schemas, or knowledge base
- Set up semantic search (Azure AI Search, Pinecone, or Weaviate)
- Test context retrieval with sample queries
For rule-based systems:
- Document business rules in a structured format
- Create a rule injection mechanism
- Build prompt templates that include context
Deliverable: AI that receives relevant governance context before making decisions.
Quick Win: Immediate reduction in out-of-scope or invalid requests. Your AI stops generating outputs that violate basic constraints.
StatSafe Example: We indexed the entire database schema in Azure AI Search. Now, when someone asks “Show me patient data,” GPT-4 knows which tables exist, what columns they contain, and what relationships matter, before generating SQL.
Time Investment: 1-2 weeks with 1-2 engineers.
Phase 2: AI Interpretation (Weeks 3-4)
Goal: Implement controlled AI generation with structured prompts and chain-of-thought reasoning.
What You’ll Build:
Prompt Engineering:
- Create modular prompt templates
- Implement chain-of-thought reasoning (for complex decisions)
- Add few-shot examples (show AI what “good” looks like)
Orchestration:
- Set up LangChain or a similar orchestration framework
- Build your first stateful workflow
- Implement conversation memory (if needed)
Deliverable: AI that generates structured, auditable outputs following your prompt design.
Quick Win: More consistent outputs. You can debug and iterate on prompts because they’re templated and version-controlled.
StatSafe Example: We built modular prompts that inject schema context, demonstrate SQL examples, and enforce output format. GPT-4 now generates consistently structured SQL that we can validate programmatically.
Time Investment: 2 weeks with 1-2 engineers.
Phase 3: Validation & Verification (Weeks 5-8)
Goal: Build the validation pipeline that catches errors before production.
What You’ll Build:
Validation Layers (3-5 layers specific to your domain):
- Layer 1: Format validation (is output structured correctly?)
- Layer 2: Business rule validation (does it follow your constraints?)
- Layer 3: Security validation (is it safe to execute?)
- Layer 4: Test execution (does it work on sample data?)
- Layer 5: Human review (for high-risk decisions)
Error Handling:
- Rejection logic for each layer
- User-friendly error messages
- Fallback mechanisms (retry with modified prompt, escalate to human)
Deliverable: Zero invalid outputs reach production. Everything is validated before execution.
Quick Win: Production incidents drop dramatically. Your team stops firefighting AI failures.
StatSafe Example: Our 4-layer validation pipeline (schema → syntax → security → dry run) catches every type of SQL error we’ve encountered. Invalid queries never reach the production database.
Time Investment: 3-4 weeks with 2-3 engineers (most time-intensive phase).
Phase 4: Execution & Monitoring (Weeks 9-12)
Goal: Deploy with full observability and strategic dashboards.
What You’ll Build:
Observability Infrastructure:
- LangSmith, Weights & Biases, or MLflow integration
- Trace every AI decision from input to output
- Set up alerting for anomalies
Strategic Dashboards:
- Executive view: success rate, failure types, risk indicators
- Technical view: latency, token usage, validation failures
- Compliance view: audit trail, decision logs, regulatory metrics
Continuous Improvement:
- Identify patterns in failures
- Refine prompts and validation rules
- Scale to additional use cases
Deliverable: Production AI system with continuous governance monitoring and executive visibility.
Quick Win: Executives can see AI performance in business terms. Compliance can audit any decision. Engineers can debug failures efficiently.
StatSafe Example: Every query is traced in LangSmith. We can show compliance officers the exact reasoning for any data access decision. Executives see a dashboard with query success rates, validation catches, and system health.
Time Investment: 3-4 weeks with 2 engineers.
Real Implementation: StatSafe Architecture Deep Dive
Let’s walk through the actual architecture of StatSafe to see these principles in action.
The Challenge
StatSafe needed to let healthcare workers query patient data using natural language. The constraints:
- HIPAA compliance required (no data leaks, full audit trail)
- Invalid SQL could break production (dangerous queries blocked)
- Non-technical users needed simple interface
- Executives needed oversight (what data is being accessed, by whom, and why)
The Solution: Layered Governance Architecture
Component 1: FastAPI Backend
Orchestrates the entire workflow. Receives natural language queries via HTTP, manages the LangGraph state machine, and coordinates between all components.
Component 2: LangGraph Orchestration
Stateful workflow controller. Determines whether input is a query, clarification, or error. Maintains conversation context. Enforces conditional logic (don’t execute invalid queries).
Component 3: Azure AI Search (RAG)
Loads database schema before AI generates SQL. Indexes table names, column names, data types, and relationships. Provides schema context to GPT-4 via semantic search.
Component 4: Azure OpenAI GPT-4o
Performs Natural Language Processing (NLP) and generates SQL with schema context already injected. Uses modular prompts with few-shot examples. Applies chain-of-thought reasoning for complex queries.
Component 5: Custom SQL Validator
Four-layer validation pipeline:
- Schema validation (valid tables/columns?)
- Syntax validation (correct SQL Server syntax?)
- Security validation (no dangerous operations?)
- Dry-run testing (executes on test data first)
Component 6: LangSmith Tracing
Every interaction is logged: user query, schema retrieved, prompt sent, SQL generated, validation results, execution metrics. Full audit trail for compliance.
Component 7: SQL Server (Production Database)
Only validated, approved queries reach production. All access is logged and traceable.
The Data Flow
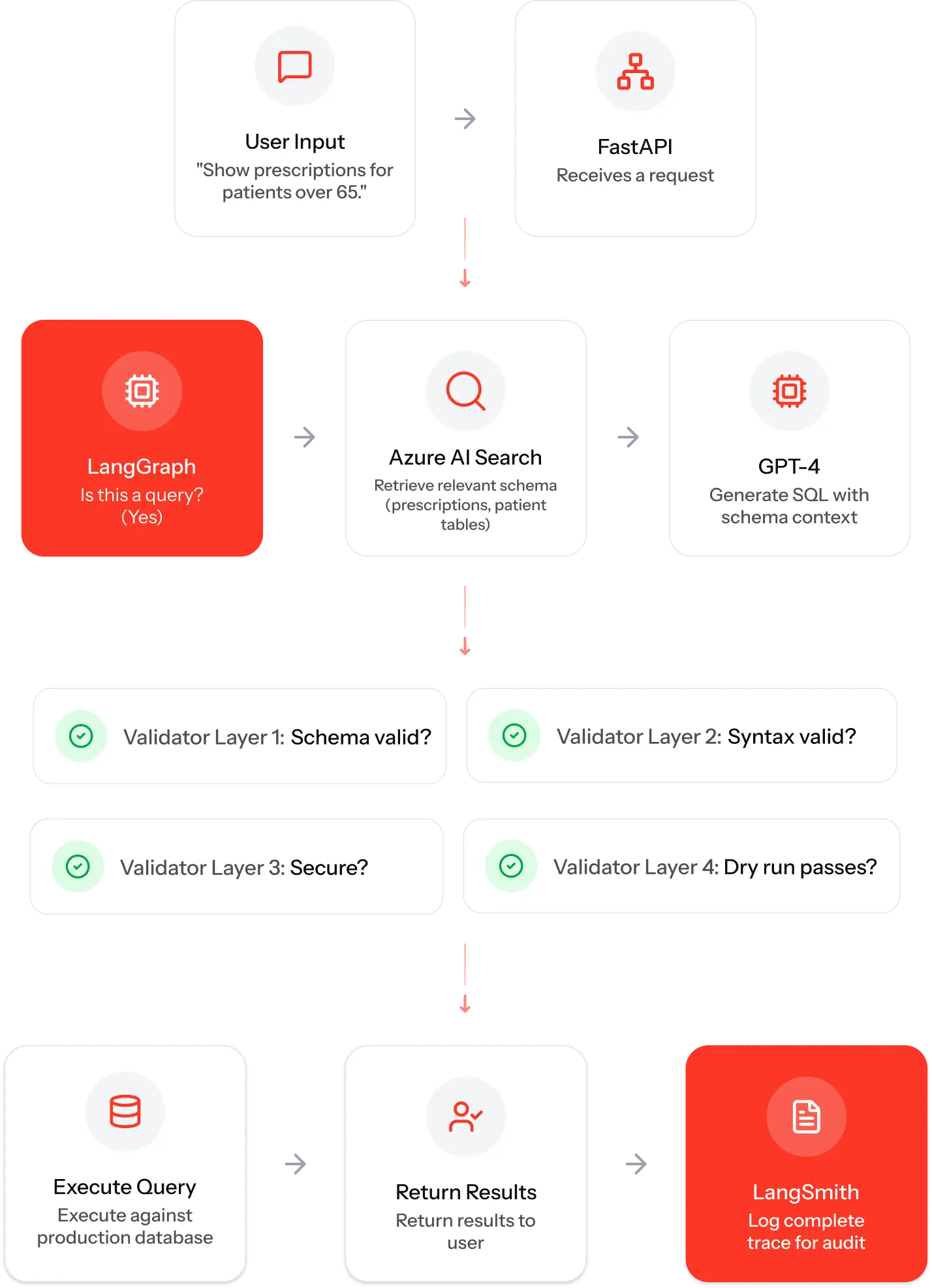
The Governance Benefits
Context-Aware: GPT-4 knows the schema before generating SQL.
Multi-Layer Validation: Four checkpoints catch errors.
Continuous Observability: LangSmith traces every decision.
Stateful Control: LangGraph maintains conversation context.
Human-Verifiable: Users see the SQL, validation results, and data preview.
Result: Production healthcare AI with zero governance incidents to date. Full HIPAA compliance. Executive visibility. Technical team confidence.
This isn’t a hypothetical framework. It’s the architecture running in production right now.
Strategic Visibility: What Executives Actually Need to See
Technical teams love metrics like loss functions, F1 scores, and token usage. Executives don’t.
When the board asks about AI governance, they want to know:
1. Are we compliant?
Show them: Audit trail completeness, validation success rate, regulatory alignment.
2. What’s the risk?
Show them: Failure rate, error types, and incidents prevented by validation.
3. Can we explain our decisions?
Show them: Example decision traces, human-readable outputs, transparency metrics.
4. Is this working?
Show them: Success rate, business impact, user adoption.
The Executive Dashboard
Your AI governance strategic visibility dashboard should include:
Governance Health Score
Single number (0-100) aggregating: validation success rate, observability coverage, compliance alignment.
Risk Indicators
Red/yellow/green status for: data access violations, failed validations, anomalous patterns.
Compliance Posture
Pass/fail status for: HIPAA, SOX, PCI, or other relevant regulations.
Decision Audit Trail
Search interface: “Show me all AI decisions related to patient X” or “Show me all high-risk approvals last month.”
Business Impact
Quantified: Time saved, costs reduced, decisions accelerated, incidents prevented.
Don’t bury executives in technical metrics. Give them a strategic context they can act on.
Common Obstacles (And How to Overcome Them)
Obstacle 1: “Governance Slows Down Innovation”
The Fear: Adding validation layers and observability will make AI deployment painfully slow.
The Reality: Built-in governance is faster than post-failure cleanup.
When you skip governance, here’s what happens:
- Deploy AI quickly
- AI fails in production
- Spend weeks debugging black-box system
- Lose stakeholder trust
- Implement governance reactively
- Rebuild parts of the system
Total time: Months. Plus reputational damage.
When you architect governance from the start:
- Build validation and observability (8-12 weeks)
- Deploy with confidence
- Catch failures before production
- Debug efficiently with traces
- Maintain stakeholder trust
Total time: 8-12 weeks. Clean deployment. No incidents.
Automated validation is faster than manual review. Proactive governance beats reactive firefighting.
Obstacle 2: “We Don’t Have Governance Specialists”
The Fear: Governance requires specialized compliance experts or governance teams we don’t have.
The Reality: Engineers can build governance architecture. Compliance reviews it.
You don’t need a governance team to implement this framework. You need:
- 2-3 engineers who understand your AI system
- Clear business rules documented by domain experts
- Basic compliance requirements identified by your legal/compliance team
The engineers build the validation layers, observability, and dashboards.
Compliance reviews that the architecture meets requirements.
Executives monitor via strategic dashboards.
Mid-market advantage: You’re small enough to move fast. You don’t need enterprise governance bureaucracy.
Use templates and frameworks (like this one) to reduce the expertise barrier.
Obstacle 3: “Too Complex for Mid-Market”
The Fear: This looks like enterprise-grade architecture. We’re a 200-person company.
The Reality: Monolithic architecture keeps it simple. Start with Phase 1-2.
StatSafe uses a monolithic design specifically to reduce complexity:
- One FastAPI application (not distributed microservices)
- Integrated validation (not separate service)
- Single observability tool (LangSmith)
- Managed services (Azure OpenAI, Azure AI Search)
You can start smaller:
Month 1: Implement context loading (RAG or rule injection)
Month 2: Add basic validation (2-3 layers)
Month 3: Deploy with observability
Don’t overthink it. Start with the principles. Scale complexity as you grow.
60-90 days is realistic for mid-market teams.
Obstacle 4: “Our AI Vendor Handles Governance”
The Fear: We use [OpenAI / Anthropic / Cohere / vendor]. They handle governance.
The Reality: Vendors provide model governance. You must own application governance.
Your AI vendor governs:
- Model training data
- Model safety guardrails
- API usage policies
You must govern:
- Business rules specific to your domain
- Data access controls specific to your schema
- Validation logic specific to your use case
- Compliance requirements specific to your industry
Example: OpenAI prevents GPT-4 from generating illegal content. They don’t prevent it from generating SQL that violates YOUR database schema. That’s your job.
Vendor tools are building blocks. Your governance architecture determines how they’re used.
When NOT to Use This Framework
This framework is designed for production AI systems where governance matters. It’s not for every use case.
Skip this framework if:
1. You’re in Early Experimentation
If you’re still validating whether AI solves your problem, don’t over-architect. Build governance when you commit to production.
2. Your AI is Low-Risk
If failures have minimal impact (chatbot for internal FAQs, content recommendations), simpler governance may suffice.
3. You’re Running Batch/Offline ML
This framework targets real-time AI systems. Batch ML (weekly model retraining, offline predictions) has different governance needs.
4. You Have < 10 AI Decisions/Day
If usage is extremely low, manual review might be more practical than automated governance.
Use this framework when:
- AI makes high-stakes decisions (healthcare, finance, security)
- You need regulatory compliance (HIPAA, SOX, PCI)
- AI runs in production with real users
- Failures have business impact (lost revenue, compliance risk)
- Executives need visibility into AI decisions
For mid-market companies deploying production AI, this is the right level of governance.
Start Where Governance Actually Starts: Your Data Architecture
AI governance isn’t optional anymore. As AI moves from pilots to production, governance becomes a competitive advantage.
Companies with governable AI deploy faster, scale confidently, and maintain stakeholder trust. Companies without governance stay stuck in pilot purgatory, afraid to deploy because they can’t control what happens.
But here’s what most companies miss: You can’t implement governance without the right data foundation.
The Reality Check: Governance Depends on Data
Look at StatSafe’s architecture again. Notice what every governance layer depends on:
- Context-Aware Generation requires indexed schemas
- Multi-Layer Validation requires data quality checks
- Continuous Observability requires data lineage
- Stateful Control requires reliable pipelines
- Human-Verifiable Outputs require data transparency
The pattern? Governance is impossible without governable data.
You can’t validate AI outputs if your data pipelines are unreliable.
You can’t trace AI decisions if your data lineage is missing.
You can’t load the governance context if your data isn’t properly structured and indexed.
You can’t implement RAG if your schemas aren’t documented and searchable.
Data Engineering & Integration isn’t just a service. It’s Phase 0, the foundation that makes Phases 1-4 possible.
Before You Tackle the 4 Phases, Ask Yourself:
For Context-Aware Generation:
- Can you index your database schemas for semantic search?
- Are your data models documented well enough to be injected as context?
- Do you have the infrastructure to implement RAG?
For Multi-Layer Validation:
- Are your data pipelines reliable enough to validate AI outputs?
- Do you have data quality checks in place?
- Can you validate schema alignment programmatically?
For Continuous Observability:
- Can you trace where your AI’s inputs come from?
- Do you have data lineage tracking?
- Are your data flows auditable?
For Stateful Control:
- Are your data pipelines orchestrated properly?
- Can your data architecture support stateful workflows?
- Do you maintain data consistency across steps?
For Human-Verifiable Outputs:
- Is your data transparent and accessible to stakeholders?
- Are data relationships clear and documented?
- Can executives understand your data flows?
If the answer to any of these is “no” or “not sure,” start with data engineering.
Conclusion: Governance First, Automation Second
The healthcare system that runs StatSafe had a choice: deploy AI fast and deal with governance later, or architect governance from the start.
They chose governance first.
Result: Production system processing sensitive patient data. Zero governance incidents. Full HIPAA compliance. Executive confidence. Clinical staff adoption.
The alternative: Fast deployment, production failures, compliance violations, executive distrust, multi-month remediation.
AI governance isn’t a speed bump. It’s the foundation that lets you deploy with confidence.
When you architect governance into your AI system, with context-aware generation, multi-layer validation, continuous observability, stateful control, and human-verifiable outputs, you don’t just reduce risk. You enable agents at scale.
Your executives trust the system because they can see it working. Your compliance team trusts it because decisions are auditable. Your engineers trust it because failures are traceable. Your users trust it because the outputs are explainable.
That’s the power of Layered Governance Architecture.
But remember: governance starts with your data foundation. Before you can implement context-aware generation, you need indexed schemas. Before you can validate outputs, you need reliable data pipelines. Before you can trace decisions, you need data lineage.
Start with Phase 0. Build the data infrastructure that makes governance possible. Then implement Phases 1-4 with confidence.
Let’s make sure your data architecture can support the governance your AI needs.
Get your data governance-ready with Pendoah’s data specialist.
In a focused 45-minute session, we’ll:
- Audit your current data infrastructure against governance requirements
- Identify which data gaps are blocking AI governance implementation
- Design the data foundation you need for context loading, validation, and observability
- Map your 8-12 week roadmap to governance-ready data architecture
- Show you examples from StatSafe and similar systems we’ve built
No pressure. No sales pitch. Just an honest assessment of whether your data architecture can support the governance you need.
Once your data foundation is solid, implementing Phases 1-4 becomes straightforward. Without it, you’re building governance on quicksand.









